MIND
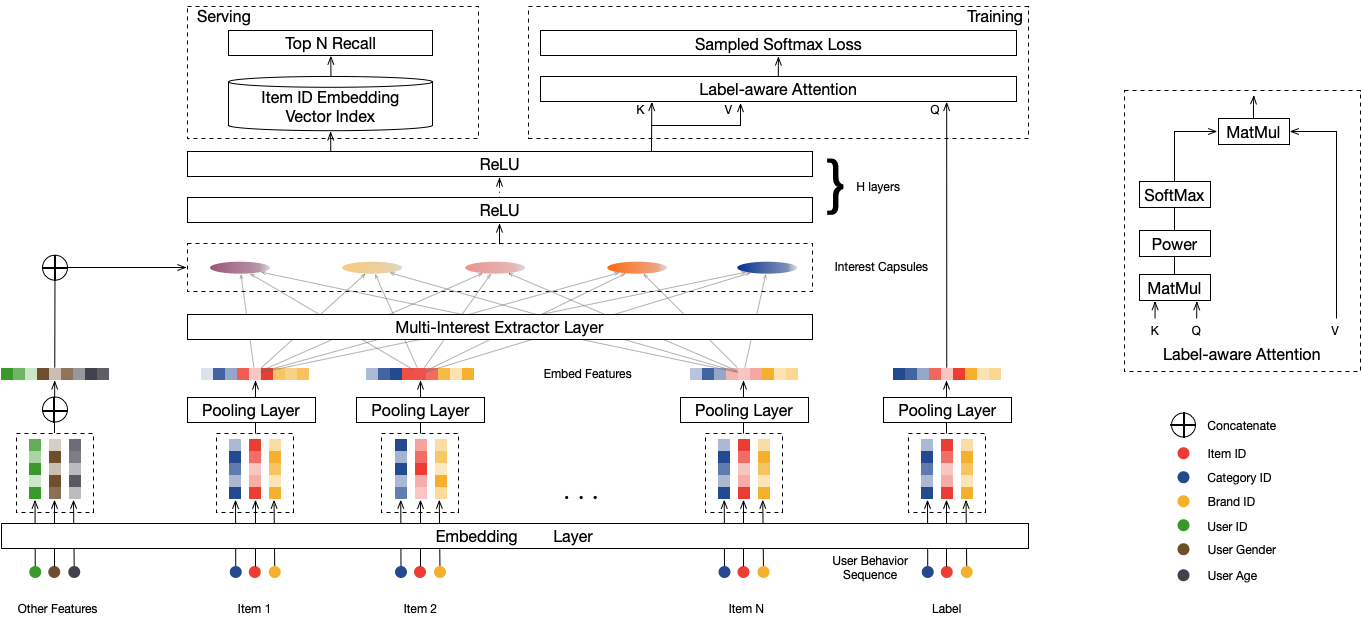
mind召回模型, 在dssm的基础上加入了兴趣聚类功能,支持多兴趣召回,能够显著的提升召回层的效果.
配置说明
feature_configs {
sequence_id_feature {
feature_name: "click_50_seq__adgroup_id"
sequence_length: 50
sequence_delim: "|"
expression: "user:click_50_seq__adgroup_id"
embedding_dim: 16
num_buckets: 846812
}
}
feature_configs {
sequence_id_feature {
feature_name: "click_50_seq__cate_id"
sequence_length: 50
sequence_delim: "|"
expression: "user:click_50_seq__cate_id"
embedding_dim: 8
num_buckets: 12961
}
}
feature_configs {
sequence_id_feature {
feature_name: "click_50_seq__brand"
sequence_length: 50
sequence_delim: "|"
expression: "user:click_50_seq__brand"
embedding_dim: 8
num_buckets: 461498
}
}
model_config {
feature_groups {
group_name: "user"
feature_names: "user_id"
feature_names: "cms_segid"
feature_names: "cms_group_id"
feature_names: "final_gender_code"
feature_names: "age_level"
feature_names: "pvalue_level"
feature_names: "shopping_level"
feature_names: "occupation"
feature_names: "new_user_class_level"
feature_names: "pid"
group_type: DEEP
}
feature_groups {
group_name: "item"
feature_names: "adgroup_id"
feature_names: "cate_id"
feature_names: "campaign_id"
feature_names: "customer"
feature_names: "brand"
feature_names: "price"
group_type: DEEP
}
feature_groups {
group_name: "hist"
feature_names: "click_50_seq__adgroup_id"
feature_names: "click_50_seq__cate_id"
feature_names: "click_50_seq__brand"
group_type: SEQUENCE
}
mind{
user_tower{
input: 'user'
history_input: 'hist'
user_mlp {
hidden_units: [256, 128]
dropout_ratio: 0.2
}
hist_seq_mlp {
hidden_units: [256, 128]
bias: false
dropout_ratio: 0.2
}
capsule_config {
max_k: 8
num_iters: 3
max_seq_len: 50
high_dim: 64
squash_pow: 0.2
const_caps_num: false
routing_logits_stddev: 1
routing_logits_scale: 20
}
concat_mlp {
hidden_units: [256, 128]
bias: false
dropout_ratio: 0.2
}
}
item_tower{
input: 'item'
mlp {
hidden_units: [256, 128]
dropout_ratio: 0.2
}
}
output_dim: 32
simi_pow: 20
in_batch_negative: false
similarity: COSINE
temperature: 0.01
}
metrics {
recall_at_k {
top_k: 1
}
}
metrics {
recall_at_k {
top_k: 5
}
}
losses {
softmax_cross_entropy {}
}
}
model_config: 配置3个feature_groups, group_name分别为’user’, ‘item’, ‘hist’(group_name可以按需自定义),分别表示user, item和user历史行为序列的输入。hist group的类型为SEQUENCE,表示输入为序列特征。
mind模型配置:
user_tower: 用户tower配置
input: 输入的feature_group 名称,即’user’
history_input: 输入历史行为序列的feature_group名称,即’hist’
user_mlp: 用户特征的mlp layer配置,包括隐藏层和BN层
hist_seq_mlp(可选): 历史行为序列特征的mlp layer配置,包括隐藏层和BN层
capsule_config: 兴趣胶囊配置
max_k(可选): 最大兴趣个数,默认为5
max_seq_len: 最大序列长度
high_dim: 兴趣向量维度
squash_pow(可选): 对squash加的power, 防止squash之后的向量值变得太小, 默认为1
num_iters(可选): 动态路由的迭代次数, 默认为3
const_caps_num(可选): 对所有用户使用相同的兴趣数量, 默认为False
routing_logits_scale(可选): 动态路由logits的初始化缩放系数, 默认为20
routing_logits_stddev(可选): 动态路由logits的初始化标准差, 默认为1
concat_mlp: 拼接用户特征和历史兴趣的mlp layer配置
item_tower: 物品tower配置,包括输入层和mlp layer
input: 输入的feature_group名称,即’item’
mlp: 物品特征的mlp layer配置,包括隐藏层和BN层。
simi_pow: 对相似度做的倍数, 放大interests之间的差异
in_batch_negative: 是否使用in-batch negative,默认为false。
similarity: u/i相似度计算方式,支持COSINE和INNER_PRODUCT,默认为COSINE。
temperature: 相似度的温度系数,默认为1.0, 如果使用COSINE similarity,建议使用更小的temperature以便提高正负样本的区分度。
output_dim: user_tower和item_tower的输出维度
示例Config
模型导出
torchrun --master_addr=localhost --master_port=32555 \
--nnodes=1 --nproc-per-node=1 --node_rank=0 \
-m tzrec.export \
--pipeline_config_path {your_model_path}/pipeline.config \
--export_dir {your_model_path}/export
模型预测
item tower推理 以本地推理为例, 如果数据在maxcompute可将路径改为对应的maxcompute表
torchrun --master_addr=localhost --master_port=32771 \
-m tzrec.predict \
--scripted_model_path ${MODEL_DIR}/export/item \
--predict_input_path data/tzrec_taobao/taobao_ad_feature/\*.parquet \
--predict_output_path ${MODEL_DIR}/item_emb \
--reserved_columns adgroup_id \
--output_columns item_tower_emb
user tower推理
torchrun --master_addr=localhost --master_port=32771 \
--nnodes=1 --nproc-per-node=1 --node_rank=0 \
-m tzrec.predict \
--scripted_model_path ${MODEL_DIR}/export/user \
--predict_input_path data/tzrec_taobao/taobao_data_recall_eval/\*.parquet \
--predict_output_path ${MODEL_DIR}/user_emb \
--reserved_columns user_id,adgroup_id \
--output_columns user_tower_emb
模型评估
read maxcompute
torchrun --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT \
--nnodes=$WORLD_SIZE --nproc-per-node=$NPROC_PER_NODE --node_rank=$RANK \
-m tzrec.tools.hitrate \
--user_gt_input odps://{project}/tables/tbl_user_gt_input \
--item_embedding_input odps://{project}/tables/tbl_item_embedding_input \
--total_hitrate_output odps://{project}/tables/tbl_total_hitrate_output \
--hitrate_details_output odps://{project}/tables/tbl_hitrate_details_output \
--item_id_field docid_int \
--request_id_field uid \
--gt_items_field docid_int \
--top_k 200 \
--batch_size 1024 \
--num_interests 8
local
torchrun --master_addr=localhost --master_port=32771 \
--nnodes=1 --nproc-per-node=1 --node_rank=0 \
-m tzrec.tools.hitrate \
--user_gt_input ${MODEL_DIR}/user_emb/part-0.parquet \
--item_embedding_input ${MODEL_DIR}/item_emb/part-0.parquet \
--total_hitrate_output ${MODEL_DIR}/hitrate_total \
--hitrate_details_output ${MODEL_DIR}/hitrate_details\
--item_id_field docid_int \
--request_id_field uid \
--gt_items_field docid_int \
--top_k 200 \
--batch_size 2048 \
--num_interests 8
user_gt_input表: 用户真实序列(ground truth)表和embedding, 包含列[request_id, gt_items, user_tower_emb]
item_embedding_input表: item embedding表, 包含列[item_id, item_tower_emb]
request_id_field: user_gt_input表中的request id的列名
item_id_field: item embedding表中的item id列名
request_id_field: user_gt_input表中的request id列名
num_interests: 用户最大兴趣个数
top_k: 召回top k个item
topk_across_interests: 当给出该参数时(该参数无需赋值),在所有的兴趣中,共召回top k个item;当不给出该参数时,则在每个兴趣中, 各召回top k个item。